
Amazon Bedrock+Pollyで英単語の発音に一工夫。カタカナ読みに変換のうえ音声として保存してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、AWS事業本部 コンサルティング部の荒平(@0Air)です。
Amazon Connectなどでよく利用される音声エンジンサービスの Amazon Polly はご存知でしょうか?
このPolly、近年はかなり発音が良くなっており、昔ほど機械音声感が無くなってきています。
本エントリでは、Bedrockを利用して英単語の発音に一工夫を入れる方法をご紹介します。
改善したいこととゴール
Pollyにそのまま英単語を読み上げさせると、理想の読み方でなかったり、発音に違和感があったりします。
例文)Amazon EC2の停止を検知しました。Amazon S3に出力されたログをAmazon Athenaのクエリで確認してください。
上手く行かない例:アマゾン イーシーニ, アマゾン エスサン として発音してしまう
Bedrockを用いた読み方の変換ステップに加えることで、以下のようにほぼ理想に近付けることができました。
arap-polly-fail.mp4 (失敗例)と arap-polly-success.mp4 (成功例)をお聴き比べください。
※ Athenaがネイティブの"アシーナ"になってしまい、日本では元の"アテナ"呼びが多いので、これはこれでチューニングが必要かもしれません。
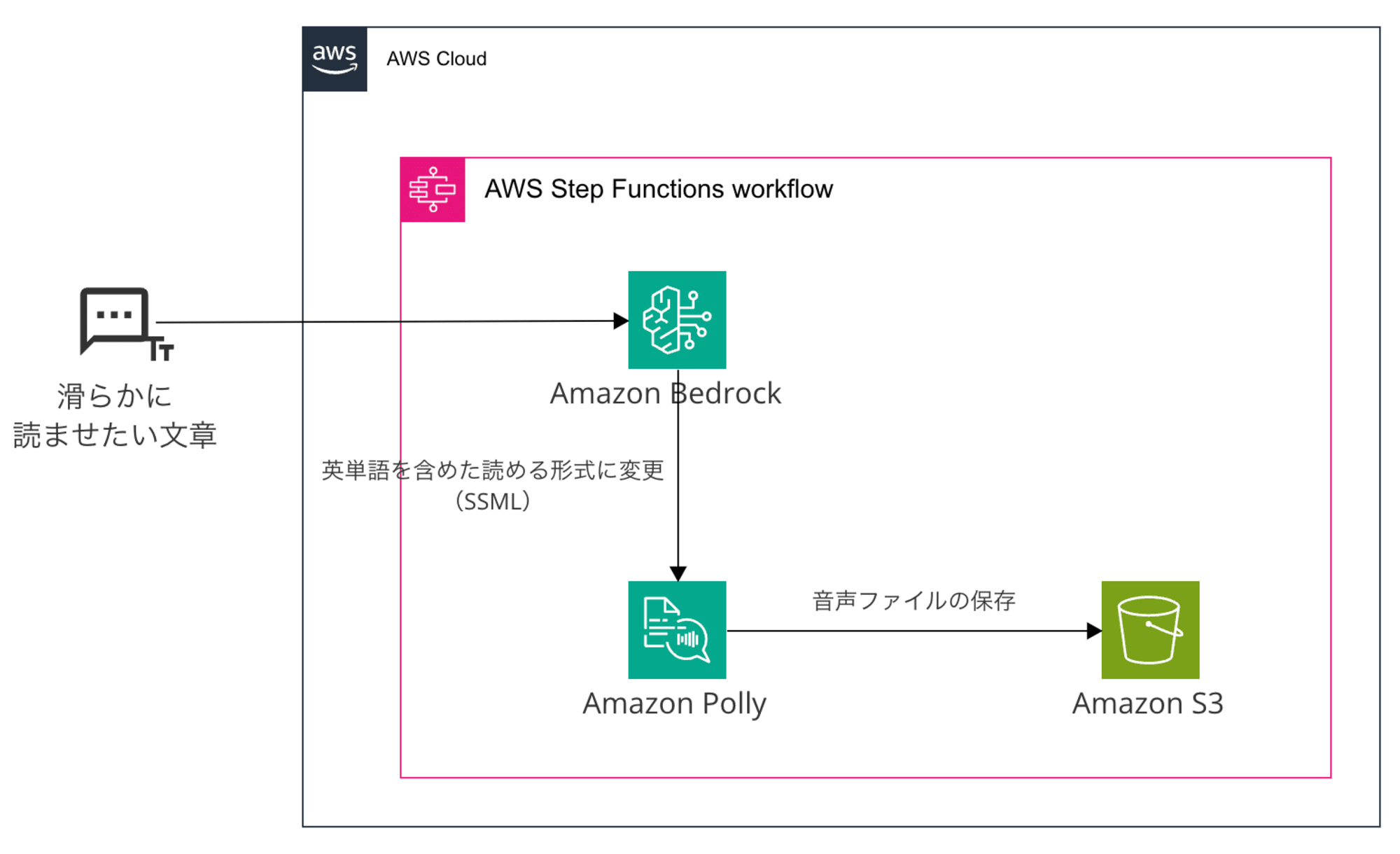
構成
英単語を含む、滑らかに読ませたい文章をBedrockにインプットし、SSML形式のAmazon Pollyが読みやすい文章に変換します。
このとき、今回英単語はカタカナに変換しました。
(※ 発音記号も試しましたが、現状のモデルでは想定通りに行くケースが少なかったです)
最終的には音声データをPollyからAmazon S3に保管します。
やってみる
Lambdaを用いてBedrockおよびPollyを呼び出すことも可能ですが、コード貼って終了、ではちょっと味気なかったのでSFnを利用することにしました。
ステートマシンが利用するIAMロールには、Pollyへのアクセス権が必要です。
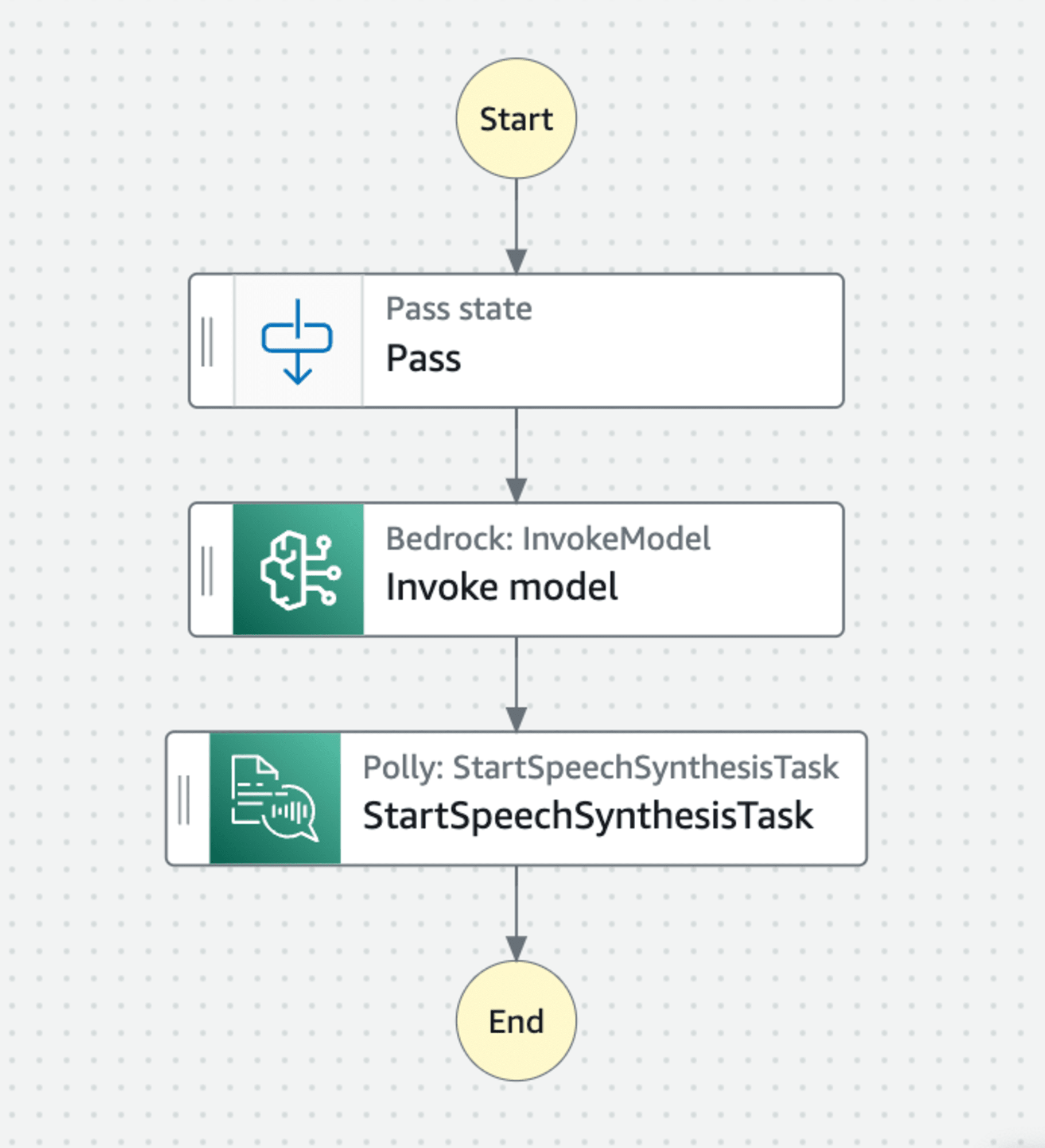
Step Functionsのステートマシン
ステートマシンは下図の通りです。まず、Passステートにシステムプロンプトを入力し、ユーザープロンプトを加工します。...(1)
Bedrock: InvokeModelのブロックでは、(1)で加工したプロンプトでBedrockのモデルを呼び出します。...(2)
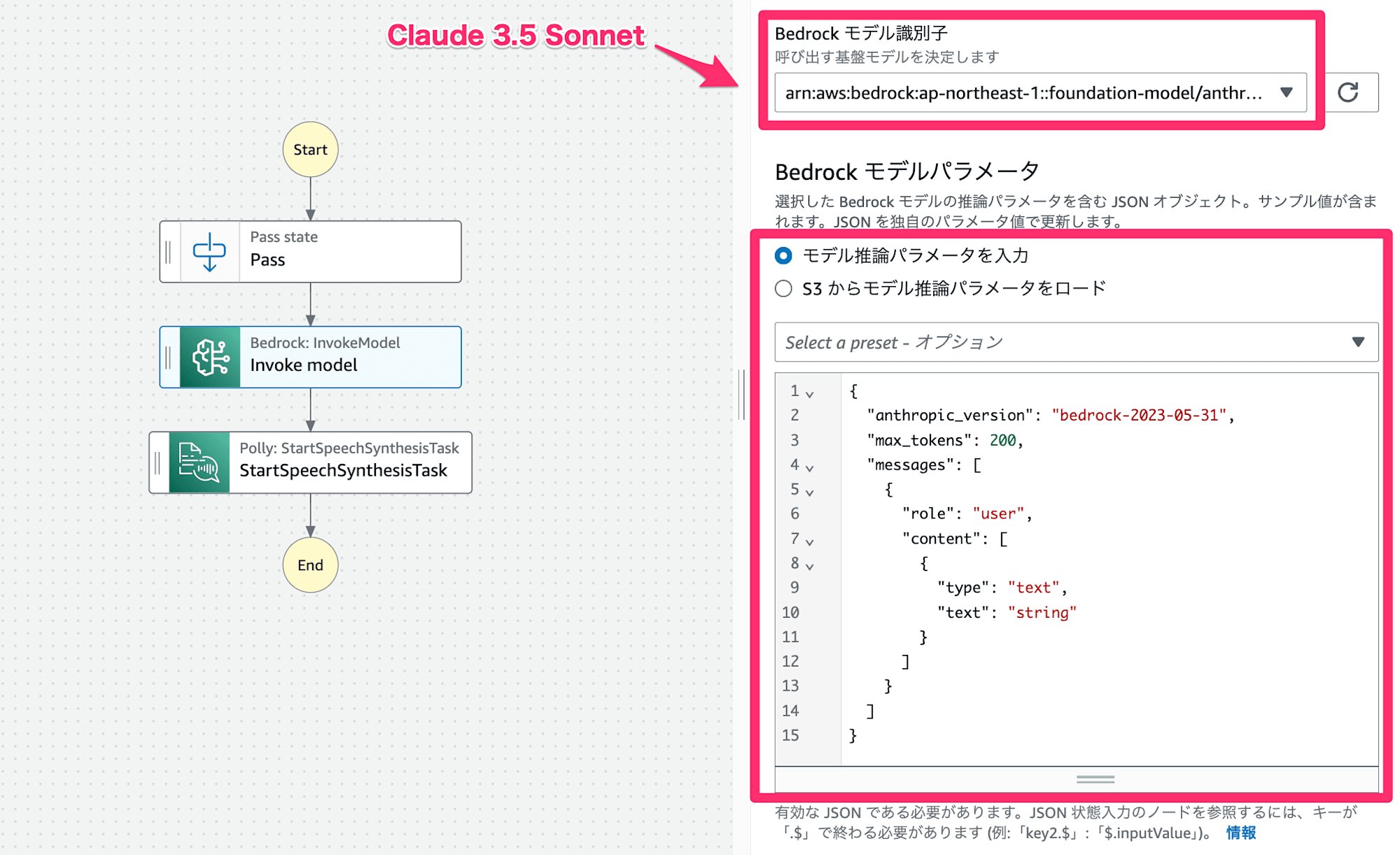
ここでは執筆時点で最新のAnthropic Claude 3.5 Sonnetを利用します。
最後に、Polly: StartSpeechSynthesisTaskブロックを利用して、(2)のテキストを音声変換してS3へ格納します。...(3)
エラー・例外処理や状態確認は省いていますので、お好みで付け足してください。
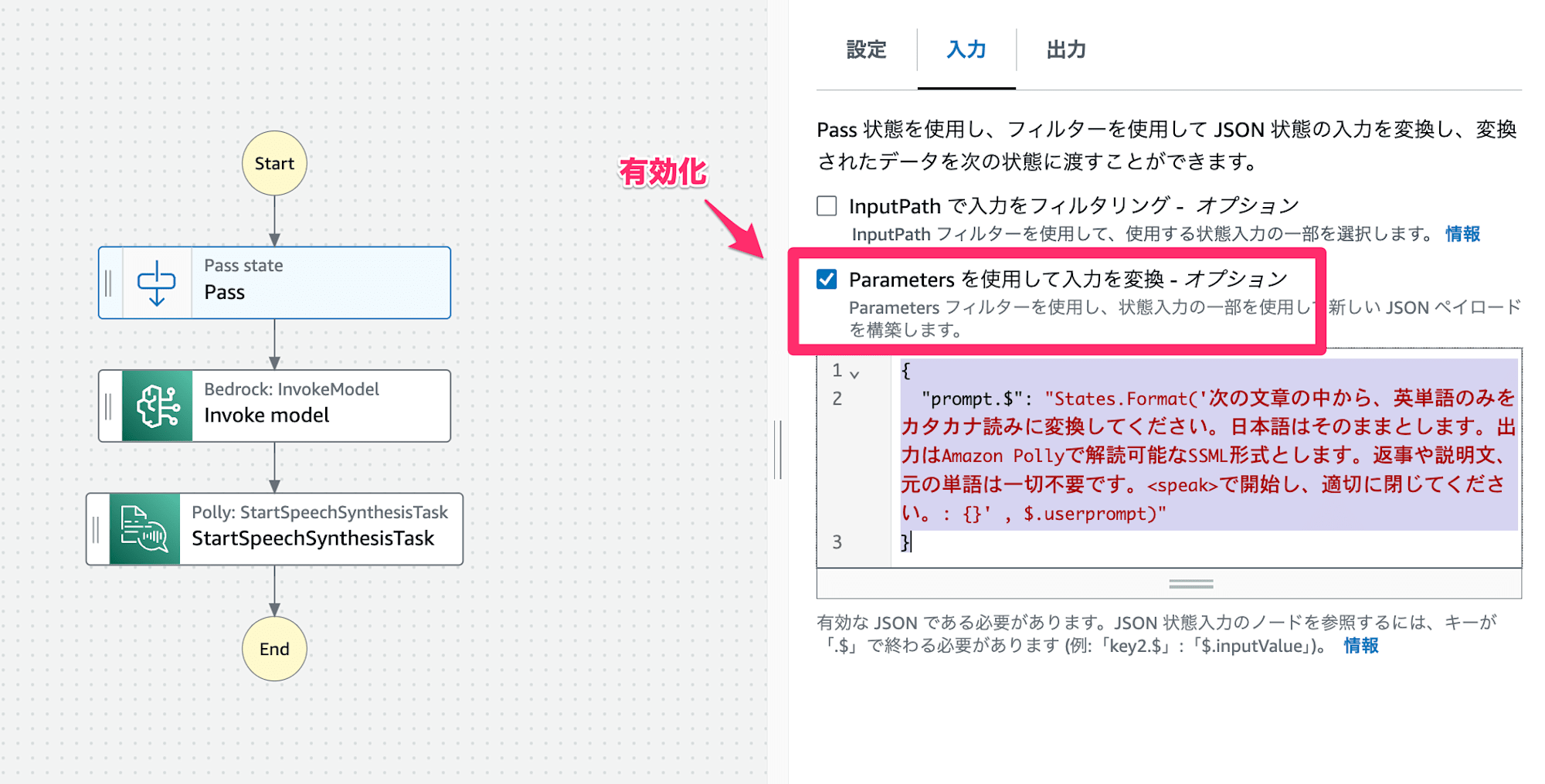
(1)Pass state
ここでは入力された文章をBedrockに投げるための前処理を行います。
「Parametersを使用して入力を変換 - オプション」を指定して、次のようなプロンプトを書いてみました。
{
"prompt.$": "States.Format('次の文章の中から、英単語のみをカタカナ読みに変換してください。日本語はそのままとします。出力はAmazon Pollyで解読可能なSSML形式とします。返事や説明文、元の単語は一切不要です。<speak>で開始し、適切に閉じてください。: {}' , $.userprompt)"
}
色々試す中で、「英単語のみをカタカナ読みにしてください」という指示だけだと全文がカタカナになったり、SSMLでもPollyが解釈できない文章がでてきたり、余計な文章が付属してきたりと色々チューニングが必要でした。
筆者はこのあたりまだ知識として足りていないので、プロンプト力のある方は是非、強化を図ってみてください。
出力設定はデフォルトのままにします。
(2)Bedrock: InvokeModel
Bedrock: InvokeModel ブロックを利用してモデルにメッセージを送ります。
前述の通り、ここでは執筆時点で最新のAnthropic Claude 3.5 Sonnetを利用します。
モデルパラメータはClaude選択時のデフォルトパラメータで問題ありません。
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 200,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "string"
}
]
}
]
}
ResultSelectorを利用して、Bedrockのレスポンスから欲しいテキストを抽出します。
{
"result.$": "$.Body.content[0].text"
}

(3)Polly: StartSpeechSynthesisTask
Polly: StartSpeechSynthesisTask ブロックを利用して音声ファイル化したものをS3バケットに保存します。
前のステートからテキスト(result)を受け取り、PollyのAPIにパラメータを渡します。
OutputFormat, OutputS3BucketName, Text, VoiceId は必須です。
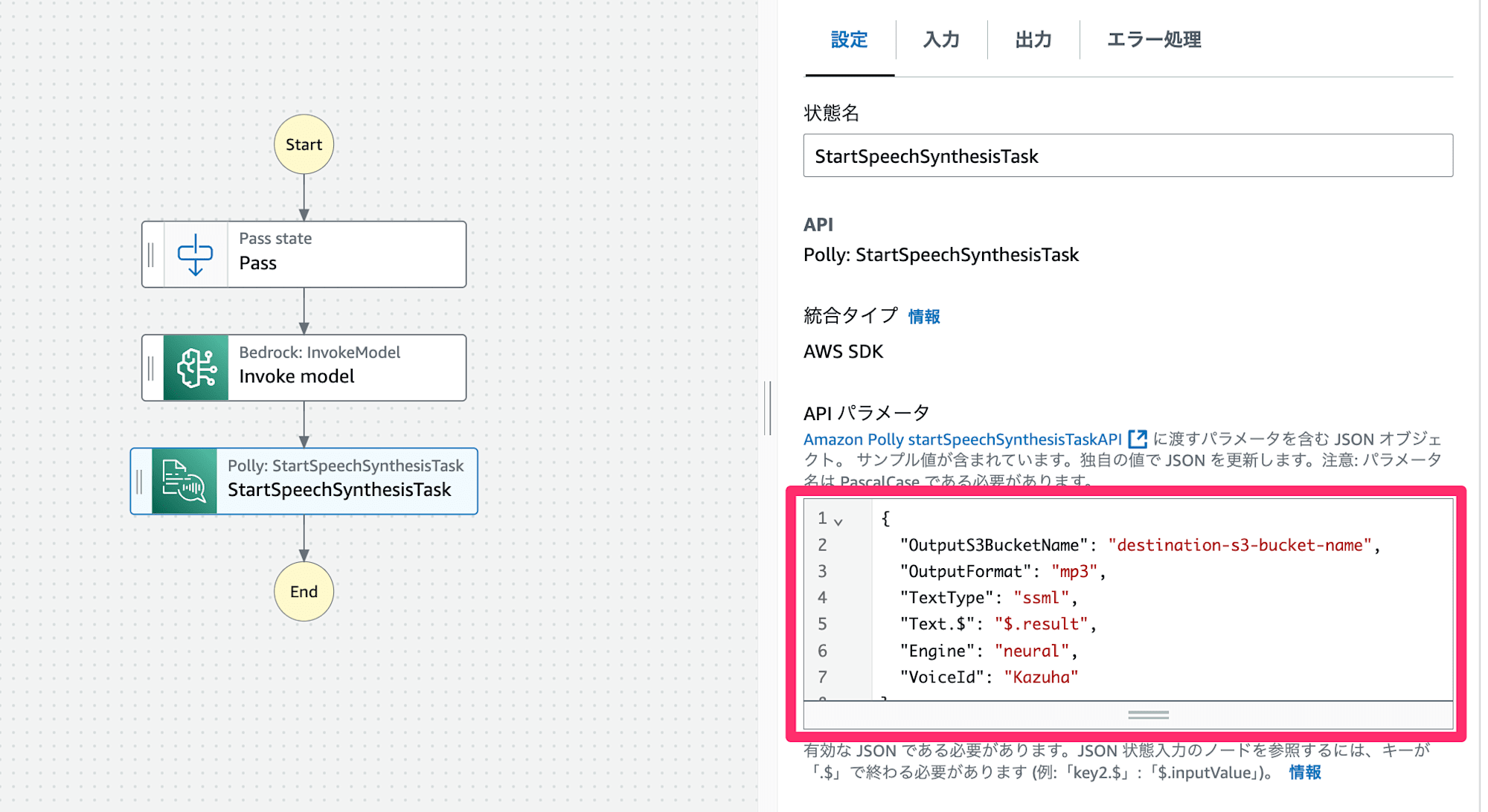
使用可能なVoiceIdは言語、音声種別によって異なるので、ドキュメントを確認してください。
日本語の場合はMizuki, Takumi, Kazuha, Tomokoの4択です。(ニューラル音声の場合、Mizuki以外の3択)
保存して実行してみる
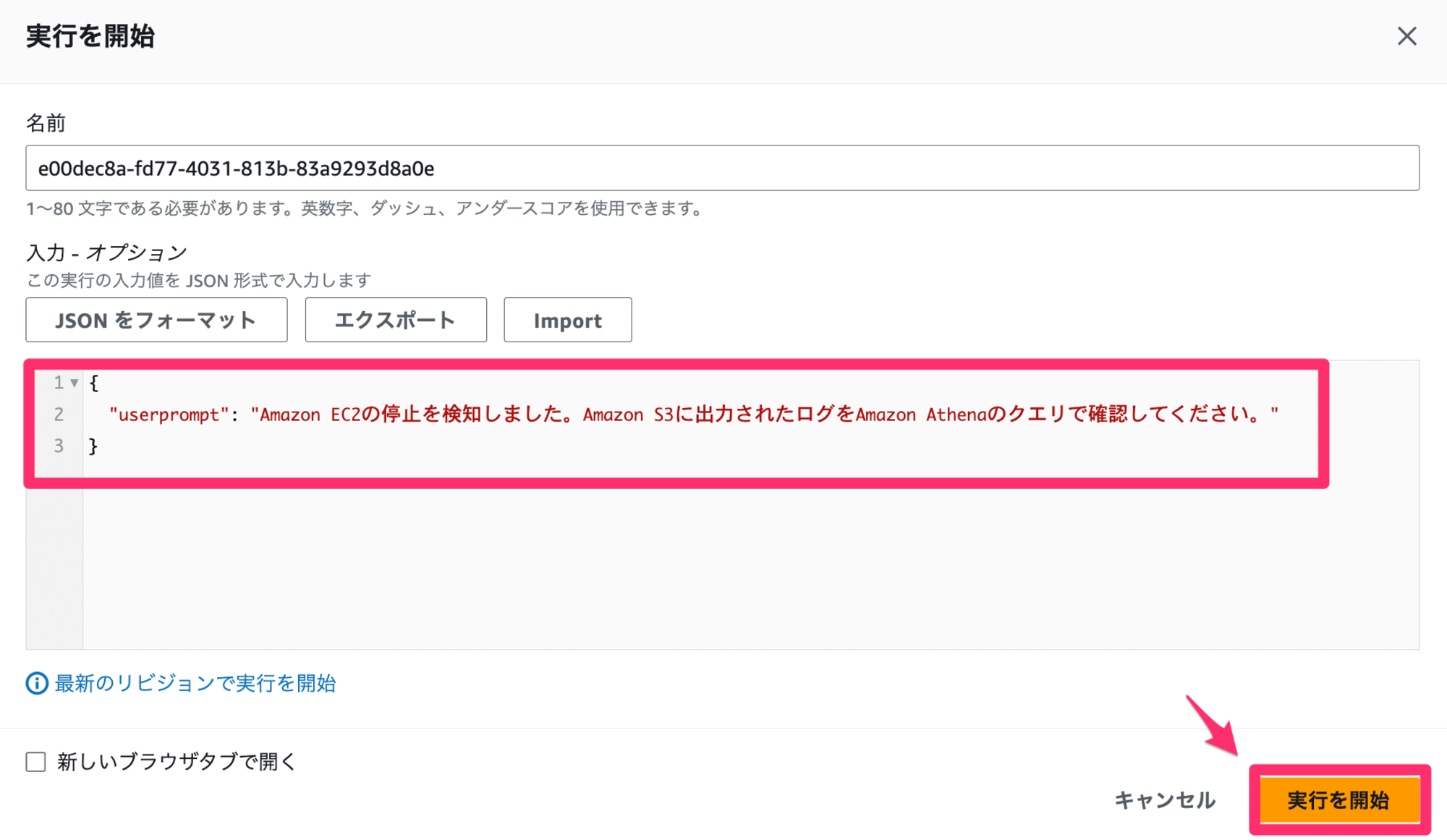
ここまでできたら、ステートマシンを保存して実行してみます。
読ませる文章何でもいいのですが、せっかくなので横文字モリモリでいきます。
{
"userprompt": "Amazon EC2の停止を検知しました。Amazon S3に出力されたログをAmazon Athenaのクエリで確認してください。"
}
音声ファイル(mp3)は指定したS3バケットの直下に保存されます。
確認すると、、、冒頭に記載した音声の通り、狙い通りの読み方になりました!
【参考】定義全体
{
"StartAt": "Pass",
"States": {
"Pass": {
"Type": "Pass",
"Next": "Invoke model",
"Parameters": {
"prompt.$": "States.Format('次の文章の中から、英単語のみをカタカナ読みに変換してください。日本語はそのままとします。出力はAmazon Pollyで解読可能なSSML形式とします。返事や説明文、元の単語は一切不要です。<speak>で開始し、適切に閉じてください。: {}' , $.userprompt)"
}
},
"Invoke model": {
"Type": "Task",
"Resource": "arn:aws:states:::bedrock:invokeModel",
"Parameters": {
"ModelId": "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0",
"Body": {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 200,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "string"
}
]
}
]
},
"ContentType": "application/json",
"Accept": "*/*"
},
"Next": "StartSpeechSynthesisTask",
"ResultSelector": {
"result.$": "$.Body.content[0].text"
}
},
"StartSpeechSynthesisTask": {
"Type": "Task",
"Parameters": {
"OutputS3BucketName": "destination-s3-bucket-name",
"OutputFormat": "mp3",
"TextType": "ssml",
"Text.$": "$.result",
"Engine": "neural",
"VoiceId": "Kazuha"
},
"Resource": "arn:aws:states:::aws-sdk:polly:startSpeechSynthesisTask",
"ResultPath": "$.result",
"End": true
}
}
}
※ 42行目:S3バケット名は環境に応じて書き換えてください。
おわりに
Amazon Pollyを使って音声加工する際、意外に思ったような発音にならないシーンがあり、毎回例外を書くのは大変なのでBedrockを組み合わせて読み方を変えてもらうことにしました。
今回はAWSのサービス名読みをサンプルとして利用しましたが、例えば日本の難読住所や、名前などにも応用できると思います。
このエントリが誰かの助けになれば幸いです。
それでは、AWS事業本部 コンサルティング部の荒平(@0Air)がお送りしました!
参考









